Virtual to Real Adaptation of Pedestrian Detectors
Luca Ciampi,
Nicola Messina,
Fabrizio Falchi,
Claudio Gennaro,
Giuseppe Amato,
Abstract
Pedestrian detection through Computer Vision is a building block for a multitude of applications. Recently, there has been an increasing interest in convolutional neural network-based architectures to execute such a task. One of these supervised networks’ critical goals is to generalize the knowledge learned during the training phase to new scenarios with different characteristics. A suitably labeled dataset is essential to achieve this purpose. The main problem is that manually annotating a dataset usually requires a lot of human effort, and it is costly. To this end, we introduce ViPeD (Virtual Pedestrian Dataset), a new synthetically generated set of images collected with the highly photo-realistic graphical engine of the video game GTA V (Grand Theft Auto V), where annotations are automatically acquired. However, when training solely on the synthetic dataset, the model experiences a Synthetic2Real domain shift leading to a performance drop when applied to real-world images. To mitigate this gap, we propose two different domain adaptation techniques suitable for the pedestrian detection task, but possibly applicable to general object detection. Experiments show that the network trained with ViPeD can generalize over unseen real-world scenarios better than the detector trained over real-world data, exploiting the variety of our synthetic dataset. Furthermore, we demonstrate that with our domain adaptation techniques, we can reduce the Synthetic2Real domain shift, making the two domains closer and obtaining a performance improvement when testing the network over the real-world images.



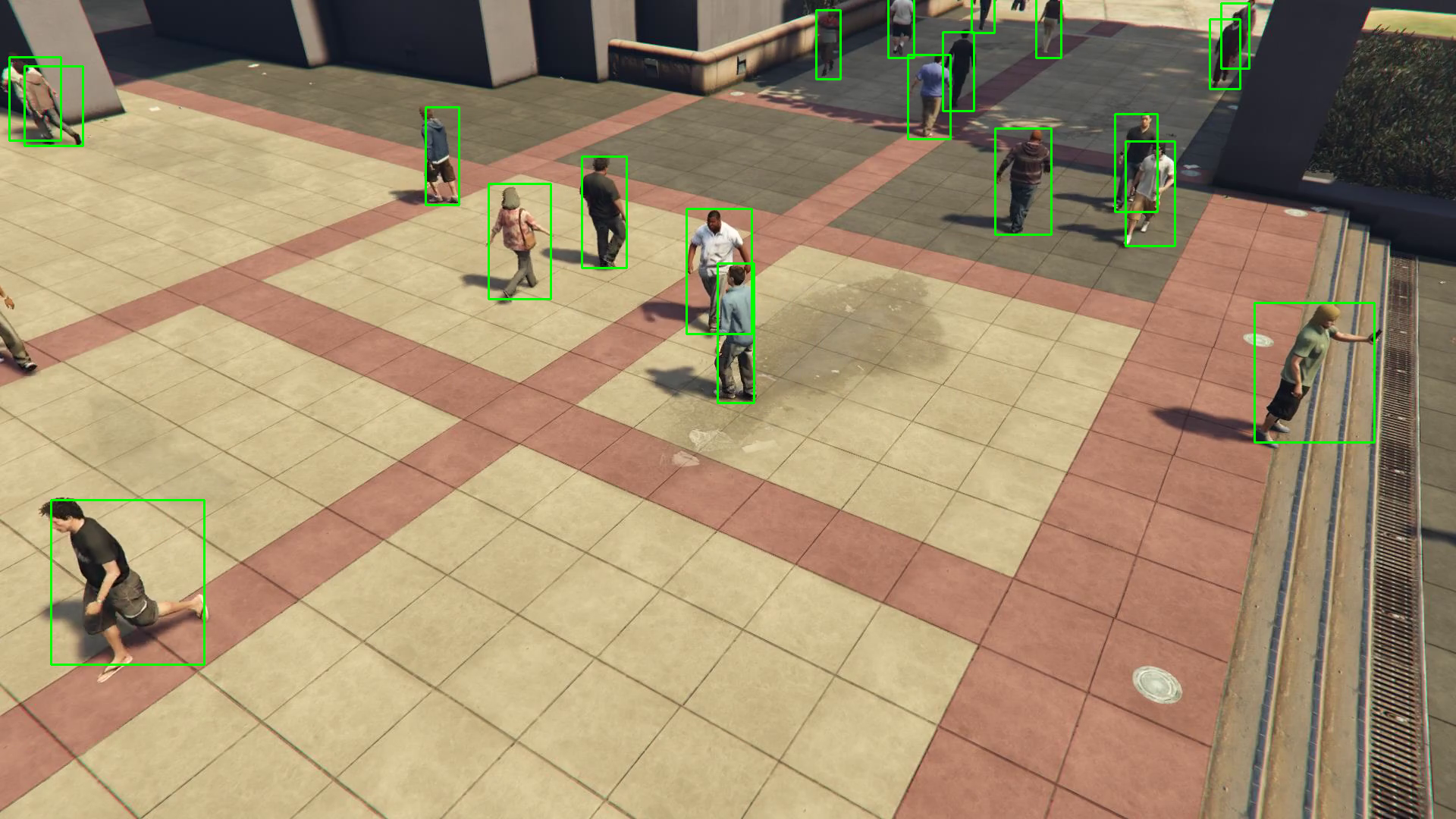
Papers
- Virtual to Real adaptation of Pedestrian Detectors (Download, 19.0MB). The paper has been published at Sensors. This is the extended version of our previous conference paper and it contains a wider experimental section and introduces an additional supervised domain-adaptation approach.
- Learning Pedestrian Detection from Virtual Worlds ( Download, 3.3MB). The paper has been presented at ICIAP 2019.
Dataset and Code
This dataset is an extension of the JTA (Joint Track Auto) dataset.
Here you can find more details about the ViPeD dataset, together with the download link.
The code for training and evaluating Faster-RCNN with our method is available in our GitHub repository.
License
ViPeD is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.Cite our work
If you find this work or code useful for your research, please cite the following:
@article{ciampi2020virtual,
title={Virtual to Real Adaptation of Pedestrian Detectors},
author={Ciampi, Luca and Messina, Nicola and Falchi, Fabrizio and Gennaro, Claudio and Amato, Giuseppe},
journal={Sensors},
volume={20},
number={18},
pages={5250},
year={2020},
doi = {10.3390/s20185250},
url = {https://doi.org/10.3390%2Fs20185250},
publisher={Multidisciplinary Digital Publishing Institute}
}
@inproceedings{amato2019learning,
title={Learning pedestrian detection from virtual worlds},
author={Amato, Giuseppe and Ciampi, Luca and Falchi, Fabrizio and Gennaro, Claudio and Messina, Nicola},
booktitle={International Conference on Image Analysis and Processing},
pages={302--312},
year={2019},
organization={Springer}
}
We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Jetson TX2 used for this research.